How Word Files Store Images
With the Microsoft Word Docx format, it’s quite easy to see how images are stored. Docx files have been the default Word format since Word 2007, and are an open document format based on xml. The docx file is a container for xml files relating to the structure and text of the file, as well as any objects or media used in the file. In this post I’m using the Microsoft xml notepad. You can use any editor to view xml files, but using something like this makes it a bit easier to see what’s going on. Learn more about how docx structures documents as xml.
Docx files are just zip files
You can unzip the file to see the structure inside
Word Docx files are really just zipped up containers for a series of xml files, and embedded objects. This means that to access the images in a docx file, we simply need to unzip it. You can do this one of two ways. Either:
- use a third party archive program such as 7zip to unzip the docx, or
- change the file extension of your docx file to ‘zip’, and right-click extract.
Inside the docx/zip file you’ll find xml data
Once you’ve unzipped the docx you’ll see something like this;
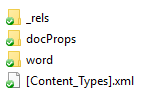 |
|---|
| How Word Files Store Images - extracted docx |
Open up the ‘word’ folder and you’ll find a series of files and folders.
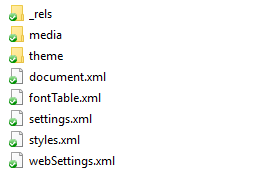 |
|---|
| How Word Files Store Images - inside word folder |
Images are in the ‘media’ folder in the unzipped docx
Inside the ‘word’ folder you’ll find another directory called ‘media’. This is where you will find any images from your docx file. You’ll see that the file names are named “Image” plus a number, which denotes the order in which they appear in the document. If you just want to extract the images for use elsewhere, then you can just copy them from this folder. If an image is used multiple times in the document, it will only appear once in this folder.
The docx xml stores properties about the images
If all you need is the images from your docx file, then you can just copy them from the ‘media’ folder. It is also possible to examine, and get additional information about the images from the xml files stored in the ‘word’ folder.
There are two xml files that contain image information
As an example I’ve made a simple docx file with an image and two lines of text.
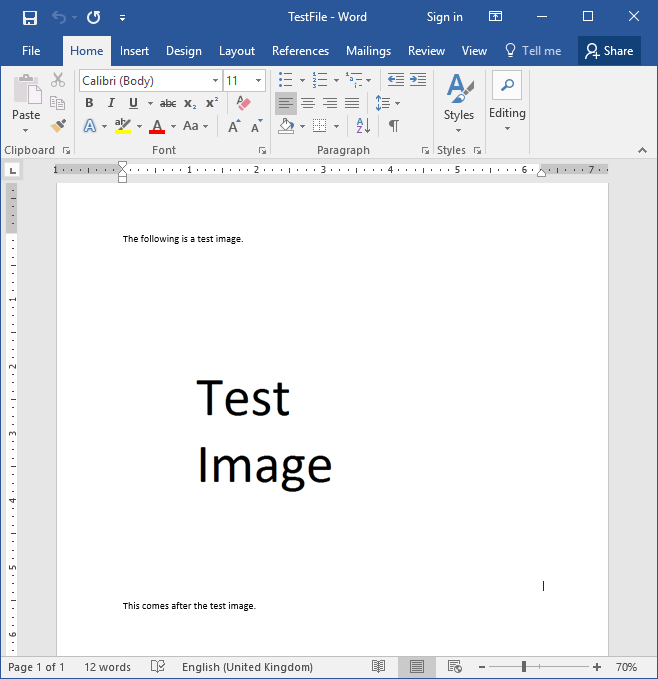 |
|---|
| How Word Files Store Images - test word file |
Document.xml
Within the ‘word’ folder in the unzipped docx document you’ll find document.xml which contains the structure of the document. Open this file up and you’ll see a series of ‘p’ – paragraph – elements which make up your document.
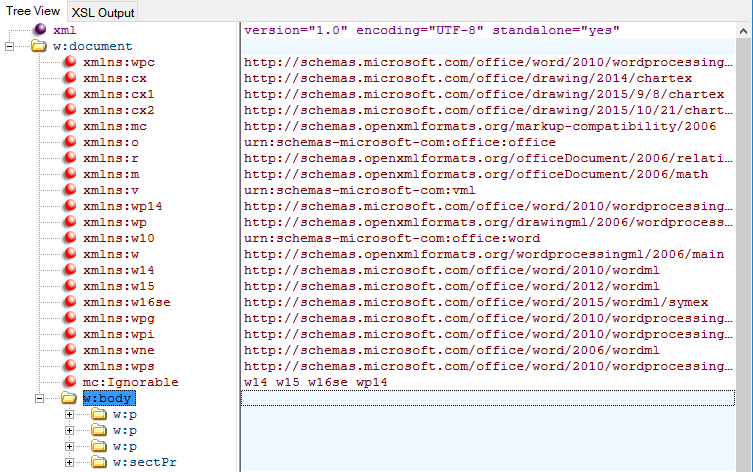 |
|---|
| How Word Files Store Images - paragraphs |
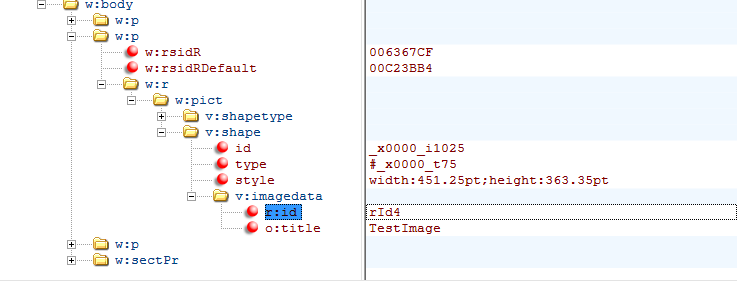
In my example document there are three p elements – one for each line of text and one for the image. In this case the image is the second of the paragraphs. We can explore the branches of this tree until we find “r:id” under “v:imagedata”.
 |
|---|
| How Word Files Store Images - paragraphs - image |
This r:id is important for using with ‘_rels’ – see relationships, below.
Relationships
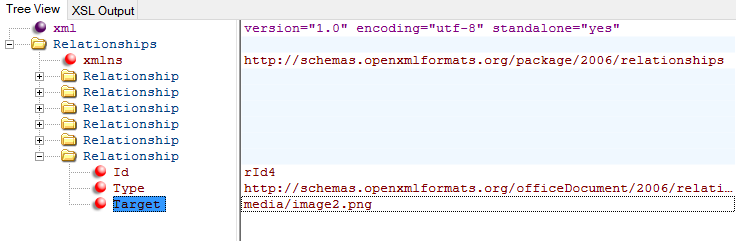
As well as the document structure in Document.xml, there are also the links or relationships between the document and other files, such as themes, fonts or images. These links are stored in the “_rels” directory. This directory contains an xml file with relationships, or links which point to the location of files needed by Document.xml. Look through the list of relationships and you’ll find “Id”, “Type” and “Target” attributes. For images, the Target attribute points to the location of image in the ‘media’ folder.
 |
|---|
| Target |
The id relates to the id we found in Document.xml. We now know where the image is found in the document (via “Document.xml”) and which image it refers to (via “_rels”) Read more about images in docx files. Watch this Youtube Video for more about working with images in https://www.youtube.com/watch?v=p9MqsEIHFXE