
Pyspark brings together the analytical power and popularity of Python with the distributed-computing capability of Spark. In this post I show how you can use a docker container with pyspark and spark pre-loaded to let you play with pyspark in a Jupyter notebook, rather than having to configure your own spark cluster first.
Use Jupyter Notebook Docker Image
You can use the jupyter/pyspark-notebook from the jupyter docker stacks archive.
Learn how to run a docker container
It’s also a good idea to pick a specific tagged version from the docker hub so that docker doesn’t always attempt to download the latest image available. I went with ’04f7f60d34a6′
You can run this with
docker run -p 8888:8888 jupyter/pyspark-notebook:04f7f60d34a6
Which will give you the jupyter notebook url to use e.g.
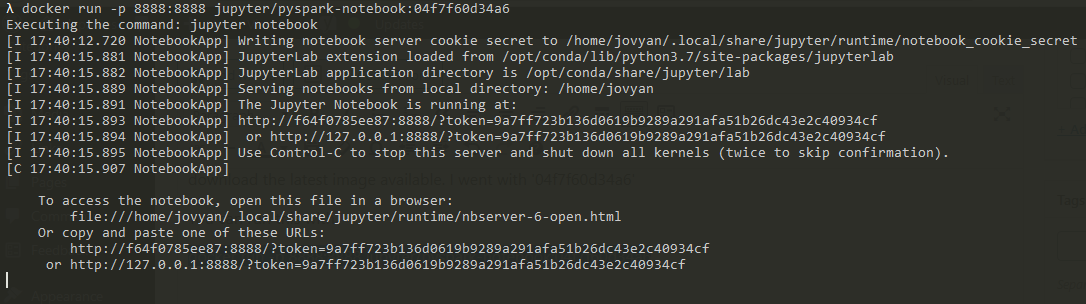
Copy and paste the url into your browser and create a new notebook and you should be good to go:
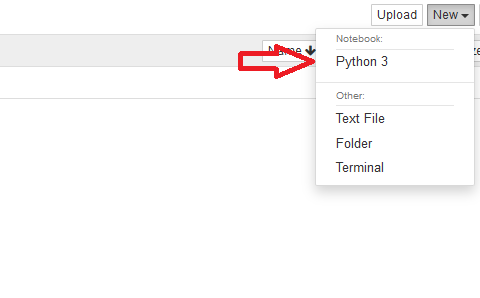
Read more about Jupyter notebook basics
Get Started With PySpark
So having started up your jupyter notebook docker image you can navigate to a notebook on your browser and get stuck in.
Confirm that pyspark is working correctly with
import pyspark
spark = pyspark.sql.SparkSession.builder\
.appName('cities')\
.getOrCreate()
populations = [
("New York", 8.3),
("London", 8.7),
("Paris", 2.1),
("Tokyo",37.9)
]
cities = spark.createDataFrame(populations, ["city", "population"])
cities.show()
Which yields
+--------+----------+ | city|population| +--------+----------+ |New York| 8.3| | London| 8.7| | Paris| 2.1| | Tokyo| 37.9| +--------+----------+
Now that you’ve got your own mini spark cluster and pyspark up and running, you can read more about what pyspark can do.
This post really is to just get started with pyspark, such as getting familiar with its api and learning how it differs to things like pandas. If you try to load anything but the smallest datasets into this mini spark-cluster you will find it is slow and may even crash the spark cluster.
If you do have problems or crash the spark cluster, simply restart the docker container and try again!