Python Text To Speech
Text to speech is a tool available in most operating systems, and helps people with reading and sight difficulties, or can be used as part of a ‘Jarvis’ helper on your computer. Python has a few options for dealing with text to speech, generally in the form of wrappers for speech engines. This post goes through a few of the options available for python text to speech. I’ve focussed on python text to speech in windows, but there are also options out there for linux and osx systems. There are already some nice summaries of python text to speech available, but hopefully this one picks up a few more package options and highlights some other functionality issues.
What is text to speech?
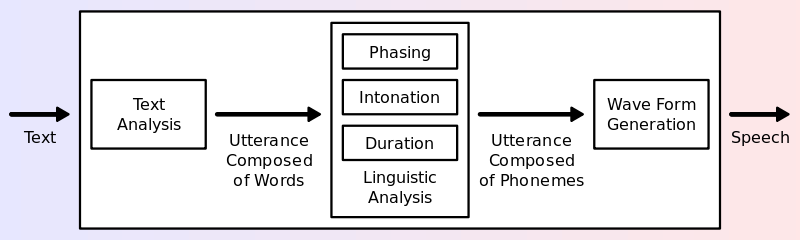
Text to speech, or speech synthesis, is a process for turning written words into audio. Text to speech systems are generaly based on a database of stored sounds which are combined together to create words and sentences. More versatile speech engines use sound elements (known as phones or dipones) which act as building blocks for whole words. These flexible speech engines can sound rather synthetic. More specialised speech engines store whole words, at the cost of some flexibility. The processing of text into speech is done by an ‘engine’. Text to speech engines work through the following steps:
- Text analysis: interpret things like numbers as words (e.g. '1' becomes 'one') and identify segments such as phrases, clauses and sentences
- Linguistic Analysis: such as identifying intonation and duration of speech
- Wave form generation: the symbolic representation of speech is converted into sound.
 |
|---|
| text to speech - speech engine |
Text to speech functionality often comes ‘baked in’ to the operating system - for example Windows uses SAPI, and Linux tends to use eSpeak. There are also some non-OS based text to speech engines out there. Google Translate offers an API which you can use as straight text to speech rather than translation, and the Java-based MaryTTS is an open source text to speech engine that you can set up as your own text to speech client-server. These speech engines typically offer different ‘voices’ which change the sound of the audio output. Windows, OSX and Linux all have a range of voices, and you can also download and install third party voices, which you can find for free or for purchase.
Python Text To Speech
Python implementations of text to speech typically provide a wrapper to the text to speech functionality of the operating system, or other speech engine. There is a range of packages out there which vary in scope, complexity and maturity. A few key features or issues that you may come across are:
- Compatability with python 2.7 and 3.x - some packages have not been actively developed or maintained for some time;
- Cross-operating system support: since text-to-speech is often OS-dependent, some developers do not attempt to support all operating systems;
- Ability to save audio outputs: some packages focus purely on the speech, while others also provide the option to save the output as an audio file.
Based on these points, I have picked out some highlights of the text to speech modules available for Python. Unfortunately, some of the fuller-featured modules are no longer maintained. I have included them here as they give a sense of what is possiblie, and might be useful in updating more recent modules.
Pytts
Pytts is a comprehensive text to speech package for Windows. Pytts has a range of features including:
- speak written text
- change voices
- save speech to a file
- adjust pronunciation
This article has some more background information about the Pytts module. Unfortunately, Pytts is no longer maintained, and is not Python 3 compatable. If these are not issues for you, then you may find that it is a good starting point, as it has features not implemented in some of these other modules. Example:
1
2
3
import pyTTS
tts = pyTTS.Create()
tts.Speak('Hello, world!')
Pyttsx
Pyttsx is similar to pytts, but is cross platform: it is compatible with Windows, OSX and Linux. Pyttsx does not seem to be as feature complete as pytts - in particular in being able to save output as a wav file, and the orignal code has not been updated in some time. There are however various forks on Github which you may find achieve what you need. Some highlights include:
- RapidWareTech/pyttsx: the original pyttsx
- jpercent/pyttsx: Fixes Python 3 compatibility. You can also follow these instructions.
- gursimar/pyttsx: a fork with some ability to save output to file (Windows only)
It doesn’t look as though there is a single fork or version which has all of these updates and features in, so you may need to pick and chose depending on your usage. Example:
1
2
3
4
5
import pyttsx
engine = pyttsx.init()
engine.say('Greetings!')
engine.say('How are you today?')
engine.runAndWait()
DeepHorizon/tts
In some ways the DeepHorizon implemenation of a python tts wrapper is not as advanced as the other ones I have listed here. What it does have is the ability to both speak as the text is being read, and save the output to file. DeepHorizon tts is only compatible with Windows. Example:
1
2
3
4
5
6
7
import tts.sapi
voice = tts.sapi.Sapi()
voice.say("Hello")
voice.set_voice("Anna")
voice.create_recording('output.wav', "This will be in a wav file")
voice.rate(-5)
voice.say("This will be said slower")
pywin32
Many of the other packages here will rely on pywin32 to communicate with Windows drivers, and it is possible to work with the package itself. You can download pywin32 from here, or see more discussion around this on Stackoverflow. You won’t have some of the convenience features provided in the other wrappers, but using pywin32 is a simple, straightforward way to achieve python text to speech, and may also be useful for troubleshooting issues. Example:
1
2
3
import win32com.client
speaker = win32com.client.Dispatch("SAPI.SpVoice")
speaker.Speak("Hello, it works!")
Mary TTS
An alternative to a pure python approach is to build on the Java-based Mary TTS. This mature project works on a client-server basis. Once you have downloaded and installed the server , you can use python to pass text to the server and retrieve the output. You can also try out Mary TTS online.
gTTS
gTTS uses the Google Translate API for TTS. I like the default Google translate voice, so this may be an attractive option in many cases. It does however put you at the mercy of Google’s control of its API, which will be of a particular concern if you are attempting a more ‘serious’ use of python text to speech. It is worth noting that, unlike the other packages I have listed, gTTS is primarily for saving the audio output, rather than speaking it directly. Example:
1
2
3
from gtts import gTTS
tts = gTTS(text='Hello, world!, lang='en')
tts.save("good.mp3")