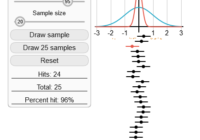
Monte Carlo Simulation
Monto Carlo simulation is a technique for approximating future behaviour based on randomly sampled numbers. By sampling from different probability distributions it is possible to use Monte Carlo simulation for a range of different situations including physical systems, computer games or finance. This post gives a simple example of Monte Carlo simulation to give some… Read More »